Understand your existing application.
Talk to the users and the programmers
review error logs
review to-do list
You need to decide if modernization is right for you.
You could replace the entire application by purchasing a package
If your existing application lacks functionality
You could recreate your application with an in-house development project
Only if your existing application is inadequate, and no package solution is available
You could modernize your existing application
Learn what data-centric programming is (link) (MVC)
Model/View/Controller
Decide if modernization is right for you.
Rank and sequence what modernization is to you
DDS > DDL (SQL)
field reference file
I/O servers
event triggers
constraints
commitment control
User Interface
All new developments should adhere to the modern application definition. There is no reason to continue with program-centric development. Once you adopt a data-centric approach, you will never revert.
Adopt an as-you-go modernize approach.
Existing applications that are currently program-centric. Will require planning
A clear understanding of the end product is required.
Theory has gotten you this far, but to get the most out of your DB, you will need to know specific techniques and have an intimate understanding of how data is defined and moved around.
Choose the AO education course or download training videos.
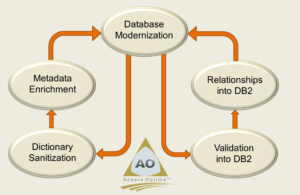
How to go about DB modernization
Big Bang – Scary
I suggest one file at a time. Starting with a simple master file for learning purposes, then moving on to the critical files.
Reference file: The AO repository standardizes data definitions.
Create a definition for the Company (not the file)
Replace prefixes by using qualifications in the programs
DDS to DDL- AO Foundation converts DDS to DDL without creating level checks
By converting the DB to SQL, you can tap into the programmers who were taught SQL at school.
SQL Long names make code easier to understand.
I/O servers: improve agility to the database by consolidating file I/O into a single program, which results in fewer programs to compile when changing a File definition
Event triggers: Before triggers validate data before adding it to the table/file. Makes the DB independent of the program
After triggers help keep data up to date in real time by replacing weekend, month-end, and year-end processing.
Constraints – enforce the data model and are part of the operating system. Just monitor for the errors.
Commitment control: Only commits the updates when all files are updated.
User Interface: Users no longer want to see the green screen. Screen scrapers are fast. JavaScript or Python may mean acquiring new programming skills to implement
These brief descriptions of the various components of modernization are short. Please reach out to me to talk about it
. There are implications associated with each of these components, which are better handled in a phone call.




